How Hotstar Scaled to 25 Million Concurrent Users
When we watch a normal video online, traffic usually comes slowly, and servers get time to adjust. Live cricket streaming is very different. At match time, millions of people open the app at almost the same moment, and this creates a huge load in just a few seconds. If the system is not prepared early, users see buffering, login failures, or even complete app crashes.
Hotstar handled this challenge during big events by thinking ahead instead of waiting for problems. Their team understood that autoscaling is useful, but autoscaling still needs time to start new servers. In live events, traffic can jump much faster than infrastructure can react. Because of this, they focused on planning and preparation before the match started.
The concurrency pattern below shows why this problem is so hard. Traffic can stay at one level and then jump very quickly, and later it can jump again to an even higher peak. This kind of behavior is risky for systems that depend only on reactive scaling.
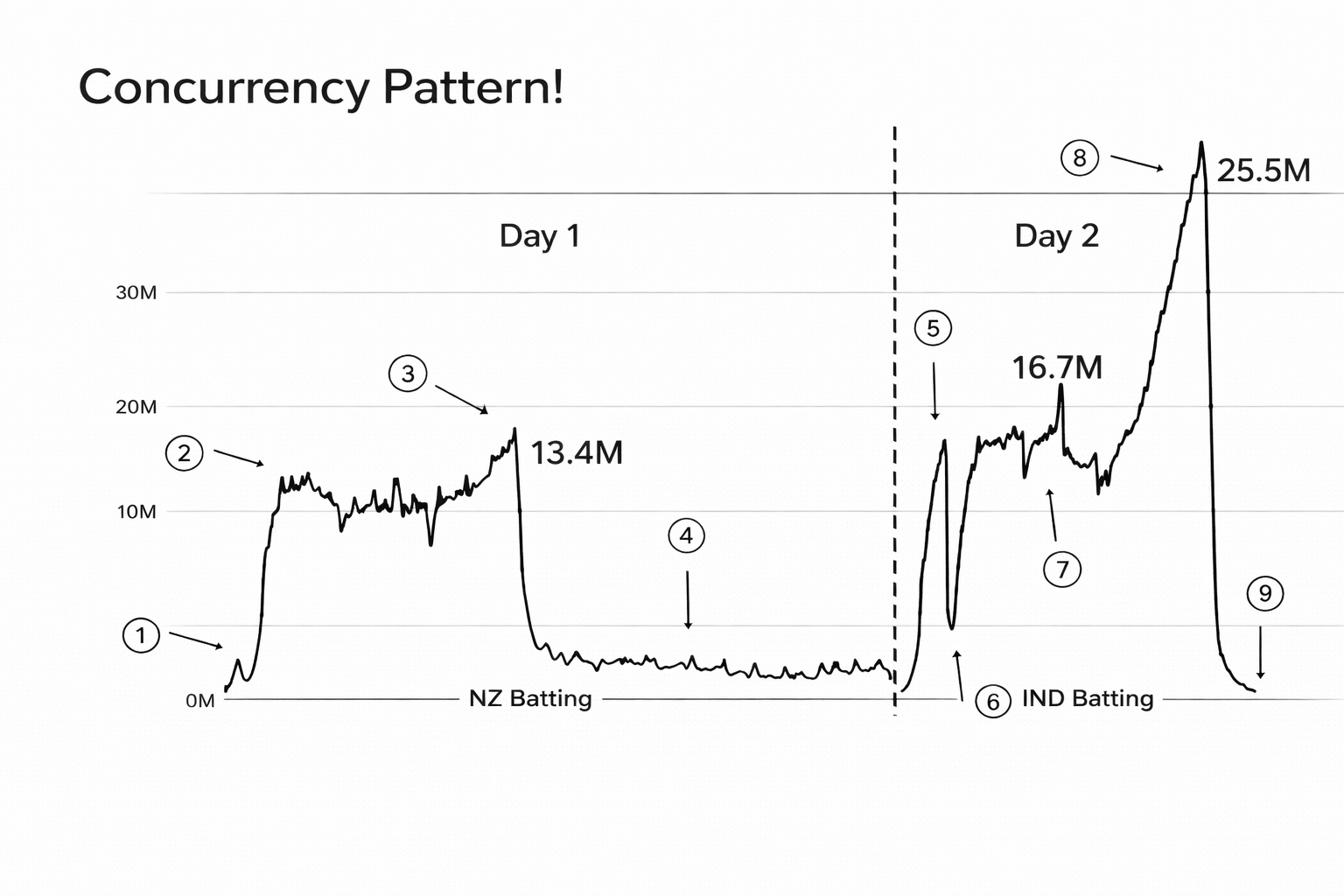
One important part was heavy load testing. Engineers created test traffic that looked like real match-day traffic and checked how every layer behaved under pressure. They tested application services, databases, network paths, and streaming delivery, and they kept improving weak areas until the platform stayed stable in extreme conditions. This gave them confidence before real users joined.
Another key step was pre-scaling. Instead of waiting for CPU alerts and then adding capacity, they brought extra resources online earlier. This means servers, caches, and supporting systems were already ready at peak time. When the first big traffic wave came, the platform did not need to panic and catch up because it had spare capacity in place.
They also used chaos testing to improve reliability. In simple words, the team purposely broke parts of the system in controlled environments to see what failed first and how quickly recovery happened. This helped them understand real failure behavior and build stronger fallback logic, so one service issue would not bring down the full user experience.
During very high traffic, Hotstar focused on what matters most for users. Core flows like video playback, login, and ad delivery got highest priority, while less important features could be reduced for some time. This kind of prioritization protects the main experience, so users can still watch the match smoothly even when the platform is under heavy stress.
CDNs were another major reason this worked at scale. Instead of serving all video from central origin systems, content was distributed closer to users through edge networks. This reduced pressure on core infrastructure and improved playback quality in different regions. For live streaming, this distribution model is critical because the same video must reach a very large audience at once.
The biggest lesson from Hotstar's story is that large-scale reliability comes from preparation, not only from powerful hardware. Teams need clear traffic forecasting, pre-event readiness, realistic testing, and feature prioritization plans. If you are building any product that can see sudden spikes, this approach is a strong example of how good engineering decisions can keep the platform stable when it matters most.
If you want to understand this in more detail, you can watch the original video source below:
How Hotstar Application Scaled 25 Million Concurrent Users | Performance Testing | Load Testing